∞ 内存价格飙涨倒逼Google改进Android系统和应用 降低对内存的需求量
从 2024 年以来内存价格就在上涨,这种上涨情况在 2025 年到现在更加夸张,例如 1GB 内存采购价从 2025 年的 2.8 美元飙升到现在的 12 美元,对于配备 16GB 内存的旗舰手机而言,仅在内存上成本就从 45 美元攀升到 192 美元,这对 OEM 而言是难以接受的。
Google将提高即将发布的 Pixel 11 售价:
Google日前已经确认即将推出的 Pixel 11 系列零售价将高于前代产品,这也让Google加入智能手机涨价的行列,不过目前产品尚未发布所以Google还未公布 Pixel 11 的最终零售价格。有零售商爆出的信息是 Pixel 11 预计起售价为 899 美元,较前代产品涨价 100 美元。
如果没有意外的话,Pixel 11 Pro 和 Pixel 11 Pro XL 零售价预计也会较前代上涨 100 美元,与此同时Google还减少了内存,泄露信息显示 256GB 版的 Pixel 11 Pro 系列内存从前代的 16GB 降低到现在的 12GB,缩减的 4GB 对Google来说也可以减少很多成本。

也在倒逼Google优化系统减少内存占用:
Google设备与服务副总裁巴尔卡特日前在接受媒体采访时透露,该公司已经启动专项计划旨在降低Android系统及其应用生态系统对内存的需求,Google的目标是在不降低用户体验的前提下,系统本身和应用程序可以以更少的内存运行。
此前微软也发布博客宣布将对 Windows 11 系统进行优化以减少内存占用,微软的目标是让 Windows 11 在中低端设备上也能流畅运行,要实现这个目的就必须对系统底层进行优化,尽可能减少系统本身对内存的占用,毕竟现在很多新推出的入门级笔记本电脑又换成 8GB 内存。
微软曾建议 Windows 11 设备至少配备 16GB 内存以实现更好的体验,不过内存涨价也让微软推出仅包含 8GB 内存的 Microsoft Surface (有评测显示这就是个电子垃圾,非常卡),而且微软还不得不违心的发文夸赞 8GB 内存也很好。
∞ Claude AI会话分享链接存在配置错误 大量包含私密内容的用户会话被Google抓取
上周末有用户发现 Claude AI 会话分享竟然出现在Google搜索中,即 A 社并未设置分享链接禁止搜索引擎抓取,因此只需要使用 SITE 指令就可以查询大量已经被Google或其他搜索引擎抓取收录的会话分享链接,部分会话分享链接中包含用户的私密信息。

需要先说明的是,这并不是 A 社后台数据库被黑,也不是用户从未分享的对话聊天记录泄露。被搜索引擎抓取的主要是用户主动生成的会话分享链接,也就是任何知道链接的人都可以公开访问对话。问题在于,很多用户理解的分享链接只是发给同事或朋友查看。
从 Web 角度来说,这类链接出现在公共网页、论坛、社交平台以及其他地方,都有可能被搜索引擎发现并公开索引,而其他用户也可以通过搜索引擎获得会话链接从而直接查看会话内容。
部分会话包含诸多敏感信息:
由于 A 社并未设置禁止搜索引擎抓取分享链接,这导致大量分享会话被Google等搜索引擎抓取,有网友测试后发现部分用户的会话分享里包含钱包私钥、违规咨询、公司任务信息以及可识别个人身份的内容。
这类信息公开到互联网上显然存在巨大安全风险,尽管 Claude 在用户分享链接时会提醒用户存在风险,但很多用户并不清楚只要生成分享链接就有可能造成会话泄露,而会话中的敏感内容也都会被其他人公开看到。
更多用户可能以为只要不把分享链接转发给未知用户就是安全的,非专业用户显然不了解搜索引擎爬虫的工作原理,所以 A 社应当设置禁止搜索引擎抓取的标识,但由于该公司并未严格设置禁止抓取,导致大量分享链接被Google、必应、Yandex 等搜索引擎成功抓取。
注:目前 A 社已经与搜索引擎提供商沟通撤掉链接,不过部分搜索引擎可能还有残留或缓存的链接,如果用户曾分享过会话且会话里包含敏感内容,建议找到会话直接删除。
目前 A 社已经修改策略禁止搜索引擎抓取:
出现这个问题的根本原因可能是 A 社存在技术配置错误,Claude 的 /share/* 路径在 robots.txt 中设置为禁止抓取,但页面响应头又设置了 X-Robots-Tag: none 属性,该属性等同于 noindex, nofollow。
这听起来像是双保险,但实际效果可能适得其反。Google官方文档明确说明,如果页面被 robots.txt 阻止抓取,搜索爬虫就无法读取页面里的 noindex 或响应头 X-Robots-Tag,结果就是搜索引擎可能抓取不到正文内容,但仍然可能因为外部链接发现 URL,然后将这个 URL 显示在搜索结果里。
于是在Google搜索里 claude.ai/share/* 路径大量 URL 被抓取并收录,但页面描述会显示没有可用信息,只不过其他用户仍然可以点击链接直接查看会话内容。
去年 ChatGPT 也出现类似问题:
2025 年 ChatGPT 大量分享链接就被发现出现在Google搜索里,OpenAI 当时也同样没有设置严格的禁止爬虫抓取,OpenAI 认为在分享时已经提醒必要的风险,只不过 OpenAI 也高估了用户的专业程度,对于大部分普通用户来说可能根本不会查看警告就直接生成分享链接。
以前百度网盘也出现过类似问题,即设置不需要密码的公开分享链接后,用户以为只要不把链接分享给其他人就是安全的,但搜索引擎爬虫同样可以抓取这些分享链接,于是用户存储在网盘里的文件也被公开曝光。
∞ RTX5060三天价格暴涨超500元
近日在京东平台上,技嘉RTX 5060 8G猎鹰OC在7月23日的页面价格还显示约2700元,7月26日已经直接标到3259元,三天时间上涨超过500元。回顾这轮涨价的传导路径,节奏之快非常罕见,7月初,上游先是传出GDDR6/GDDR7显存提价的消息,7月23日左右,英伟达通知AIC厂商上调GPU核心加显存套件的出货价,仅仅过了几天,终端零售报价就做出了反应。
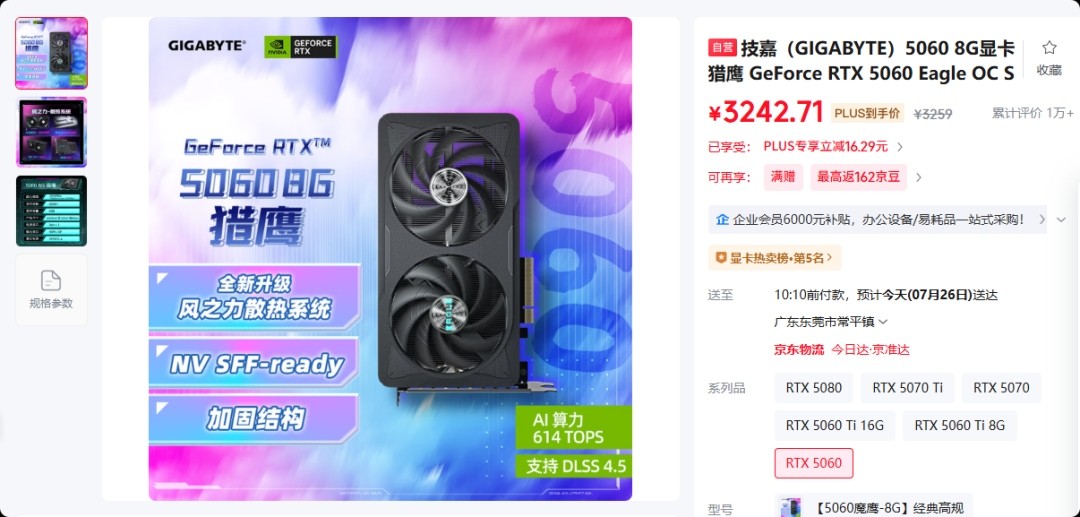
同一时间段,二手市场也出现明显异动:闲鱼上RTX 5060 Ti 8G的行情从之前约2500元跳升至约3200元,而RTX 5060 8G目前仍维持在约2500元左右(以上均为用户当天观察价,不代表全市场均价),与京东新品之间拉开了一截差价。
但这种滞后通常维持不了太久,新品价格一旦站稳高位,二手挂牌价上移只是时间问题,目前RTX 5060 8G这个价位很可能是短期内最后的相对低价。
当然,"相对低价"并不等于便宜,一张中端显卡的二手行情逐渐逼近甚至反超当初的发布指导价,本身就说明市场已经偏离了正常轨道。

从整个市场来看,造成此次5060甜品级显卡涨价的核心原因依然是AI产业。DRAM制造商正把越来越多的产能分配给高带宽的HBM,消费级显存的供应被持续挤压,这已经不只是NVIDIA一家的问题,而是整个存储芯片供应链的结构性矛盾。
换句话说,这轮涨价不是短期供需错配造成的波动,也就很难指望它快速回落。
对于有装机计划的玩家,眼下无非两条路。近期必须用卡的,要么趁二手RTX 5060 8G尚未跟涨尽快入手,要么转投价格依然平稳的上一代产品,RTX 4060等型号应付1080p到2K的主流游戏依然够用。
手里有卡、单纯想升级的,则完全没必要现在跟进高位,显存价格的回调周期通常以季度计算,此时入场很可能正好买在未来半年的价格顶点上,等这波成本传导彻底落地之后再做打算也不迟。
∞ 微软AI算力先保自家Copilot Azure客户只能分剩余容量
7月27日消息,微软正在把有限的AI算力优先留给自家产品,包括Microsoft 365 Copilot和GitHub Copilot,Azure云客户排在更后面。Business Insider报道称,这种分配顺序正在让萨蒂亚·纳德拉(Satya Nadella)面临上任以来少见的压力:微软一边大举建设AI基础设施,一边仍然赶不上内部产品和外部客户的需求。

报道援引微软首席财务官艾米·胡德(Amy Hood)今年1月在财报电话会上的说法称,公司会先满足自家AI产品增长所需的算力,其次是长期研发和创新,最后才是Azure客户需求。这意味着微软不只是向客户出售AI算力,还要先保证自己的办公和编程等AI产品持续运行;对于云客户来说,他们买的是微软云服务,但最紧缺的AI资源未必能优先轮到自己。
微软当前的核心矛盾是,AI需求增长快于数据中心和芯片容量扩张。胡德在财报电话会上曾举例说,如果把该财年上半年上线的GPU全部分配给Azure,Azure增长率本可以超过40%,而不是实际的39%。这个数字差距看起来不大,但它暴露出微软内部的取舍:同一批算力,是先支撑Azure客户,还是先支撑Microsoft 365 Copilot、GitHub Copilot等自家产品。
Business Insider报道称,Azure销售团队今年的销售配额最多被上调30%,但算力供应仍是内部持续平衡的问题。Business Insider援引知情人士称,在GitHub经历一系列故障后,微软曾借助亚马逊的云容量缓解压力,也探索过租用甲骨文基础设施,但后者因安全和合规顾虑未能推进。
这对Azure客户的影响不是“微软云不能用”,而是AI时代的云资源变得更像稀缺货。企业客户想训练模型、部署AI应用,可能会发现自己和微软自家AI产品在争同一种资源。
微软三年前因押注OpenAI被视为AI浪潮中的领先者。纳德拉在2023年2月发布AI驱动的必应搜索,随后又把生成式AI接入Office、Windows、GitHub等核心产品。但当AI从发布会走向日常使用,压力也从“有没有产品”变成“产品能不能稳定、便宜、持续地跑”。
办公软件是一个例子。Microsoft 365长期是微软最稳定的现金来源之一,但越来越多用户开始在AI工具里写文档、做总结、生成表格和演示内容。微软需要让Copilot留在办公入口里,就必须给它分配足够算力。
开发者工具也是一个例子。GitHub Copilot有先发优势,但Cursor、Anthropic的Claude Code等AI编程工具正在抢用户。Business Insider报道称,微软内部已讨论如何改革GitHub以应对竞争;与此同时,GitHub今年经历了多次重大服务故障。在AI使用量快速增长的背景下,如何扩充基础设施并保持稳定,也成为微软需要同时处理的问题。
算力短缺也迫使微软重新调整组织分工。纳德拉把更多商业业务交给贾德森·阿尔托夫,自己和核心工程团队则进一步聚焦AI。不过,对微软而言,真正棘手的仍是资源分配:既要保证自家Copilot产品不掉队,又不能让购买Azure服务的企业客户长期拿不到所需容量。
纳德拉曾因提前押注AI获得掌声,现在要面对的却是AI成功之后的资源难题:当自家Copilot、研发团队和Azure客户争夺同一批GPU时,微软必须决定,有限算力首先为哪一门生意服务。
∞ 时隔8年,“QQ宠物”回来了
还记得在桌面陪伴你的QQ宠物吗?你印象里的它是不是还停留在这个样子?停运8年后,它重新回来了。今天(7月27日),腾讯全新QQ宠物正式上线。

在Android和 iOS 端手机 QQ 打开功能入口,或者直接搜索“QQ宠物”,即可进入。用户可选择多种类型的宠物,包括原版经典的企鹅形象,还可以给它起昵称、选择性格,保留了 喂食、洗澡、打工等玩法,但取消了死亡机制。

资料显示,新版QQ宠物全面3D化,除企鹅外,新增“狗狗”与“蒜头鹅”物种;玩法上保留喂食、洗澡、打工等经典养成,但取消了死亡机制,新增和好友宠物互踩续火花等功能。

新版宠物还接入了大模型:支持性格预设,打破传统"固定反馈"模式;每日输出“宠物日记”,让养宠体验更沉浸。

原版《QQ宠物》于2018年9月底正式停止运营,这是腾讯推出的虚拟社区养成游戏,游戏过程贯穿宠物成长全程。玩家可以对宠物进行喂食、清洁,让其打工、学习、游戏、结婚、生蛋、旅游等。

QQ宠物重新回归
你还会继续养它吗?